
Google AI:构建未来智能世界的创新引擎
Google AI:构建未来智能世界的创新引擎谷歌作为全球领先的科技公司,在 AI 领域拥有深厚的积累和卓越的创新能力,在谷歌眼里,生成式 AI 带来了哪些机会?Google AI 是如何在谷歌产品中落地的?Google Cloud 提供了一系列工具和平台,如何帮助开发者构建和部署自己的专属 LLM 和 Agent?负责任的 AI 为企业带来哪些价值?
来自主题: AI资讯
10592 点击 2024-06-28 16:44
 搜索
搜索
谷歌作为全球领先的科技公司,在 AI 领域拥有深厚的积累和卓越的创新能力,在谷歌眼里,生成式 AI 带来了哪些机会?Google AI 是如何在谷歌产品中落地的?Google Cloud 提供了一系列工具和平台,如何帮助开发者构建和部署自己的专属 LLM 和 Agent?负责任的 AI 为企业带来哪些价值?
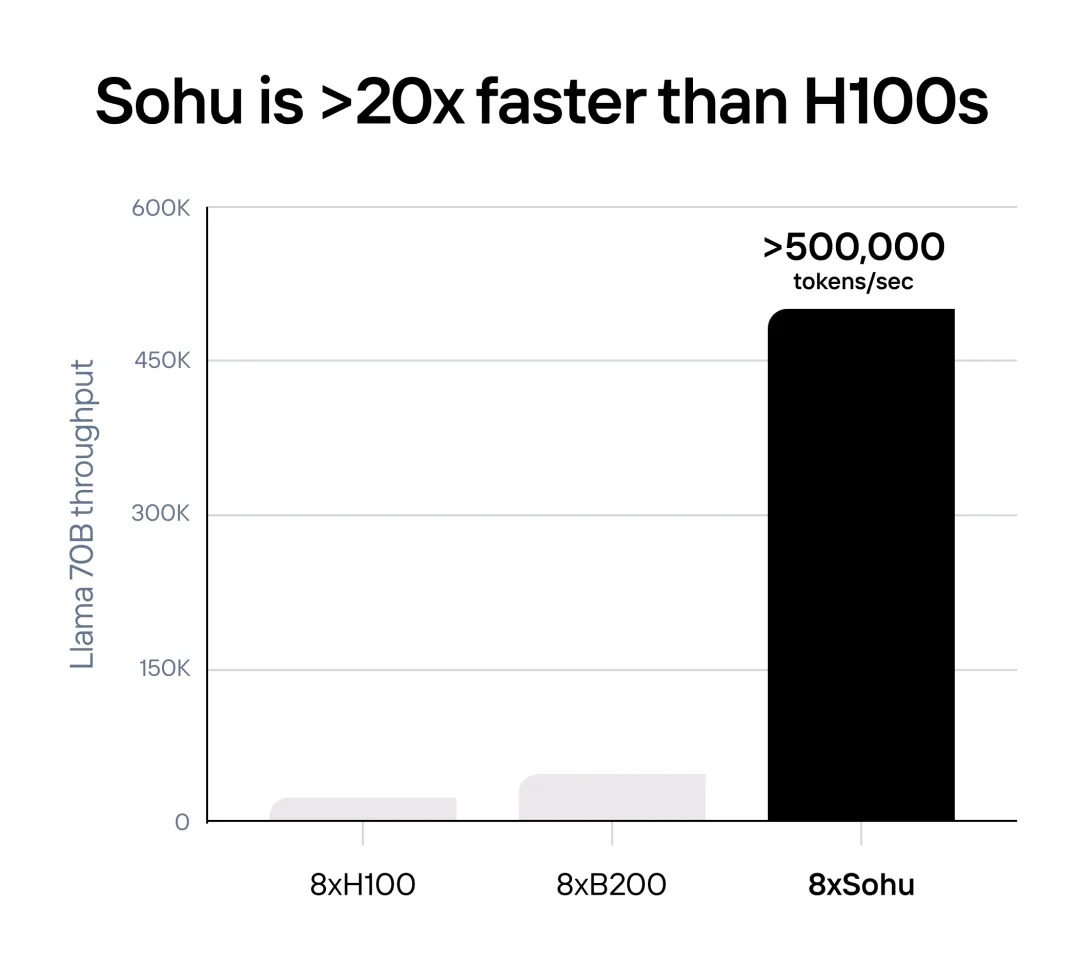
生成式 AI 推理性价比是 GPU 的 140 倍。

Cloudflare最近宣布AI Gateway已普遍可用。AI Gateway作为管理和扩展生成式AI工作负载的统一接口,让开发人员能够监控和控制AI应用程序。

在云计算领域竞争最激烈的时代,亚马逊云科技曾提出,云计算的普惠是技术升级带来的。这个说法换到如今的生成式 AI 时代也是成立的。

本周,生成式 AI 的竞争达到了新的高潮。

最近一段时间,端侧生成式 AI 上游的「军备竞赛」异常激烈。
尽管苹果在生成式 AI 方面的进展没有像谷歌、Meta 和微软等竞争对手那样高调,但该公司一直在进行相关研究,其构筑新生态的思路总是显得与众不同。

随着生成式 AI 模型掀起新一轮 AI 浪潮,越来越多的行业迎来技术变革。许多行业从业者、基础科学研究者需要快速了解 AI 领域发展现状、掌握必要的基础知识。

生成式 AI 可以对话、写诗、画图、做视频、作曲、写代码......
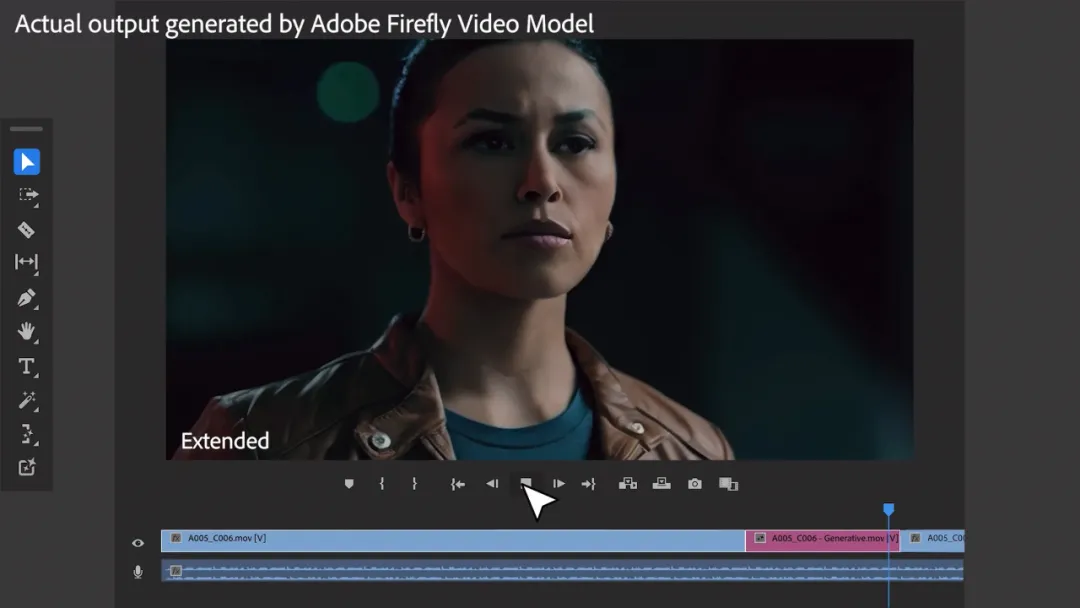
Adobe 全家桶马上就要拥有最先进的生成式 AI 视频创作能力了